ネットワークのトラブルシューティングは、残念ながら、非常に難しくややこしい作業です。ネットワークの問題は、クラウドのいくつかの場所で問題となりえます。論理的な問題解決手順を用いることは、混乱の緩和や迅速な切り分けに役立つでしょう。この章は、あなたがものにしたい情報を提供することを目標とします。
コンピュートノード上でnova-networkが動いている場合、次のコマンドでIPやVLAN、また、インターフェイスがUPしているか、などインターフェイス関連の情報を見られます。
# ip a
もしあなたがネットワークの問題に直面した場合、まず最初にするとよいのは、インターフェイスがUPになっているかを確認することです。例えば、
$ ip a | grep state 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master br100 state UP qlen 1000 4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN 6: br100: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
virbr0の状態は無視することができます。なぜならそれはlibvirtが作成するデフォルトのブリッジで、OpenStackからは使われないからです。
もしあなたがインスタンスにログインしており、外部ホスト、例えば google.comにpingした場合、そのpingパケットは下記経路を通ります。
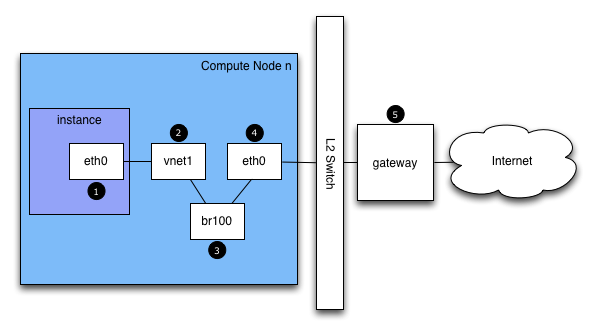
インスタンスはパケットを生成し、インスタンス内の仮想NIC、例えば eth0にそれを渡します。
そのパケットはコンピュートホストの仮想NIC、例えば vnet1に転送されます。vnet NICの構成は、/etc/libvirt/qemu/instance-xxxxxxxx.xml を見ることで把握できます。
パケットはvnet NICからコンピュートノードのブリッジ、例えば
br100に転送されます。もしFlatDHCPManagerを使っているのであれば、ブリッジはコンピュートノード上に一つです。VlanManagerであれば、VLANごとにブリッジが存在します。
下記コマンドを実行することで、パケットがどのブリッジを使うか確認できます。
$ brctl show
vnet NICを探してください。また、nova.confのflat_network_bridgeオプションも参考になります。
パケットはコンピュートノードの物理NICに送られます。このNICはbrctlコマンドの出力から、もしくはnova.confのflat_interfaceオプションから確認できます。
パケットはこのNICに送られた後、コンピュートノードのデフォルトゲートウェイに転送されます。パケットはこの時点で、おそらくあなたの管理範囲外でしょう。図には外部ゲートウェイを描いていますが、マルチホストのデフォルト構成では、コンピュートホストがゲートウェイです。
pingの応答経路は、これと逆方向です。
この経路説明によって、あなたはパケットが4つの異なるNICの間を行き来していることがわかったでしょう。これらのどのNICに問題が発生しても、ネットワークの問題となるでしょう。
ネットワーク経路のどこに障害があるかを素早く見つけるには、pingを使います。まずあなたがインスタンス上で、google.comのような外部ホストにpingできるのであれば、ネットワークの問題はないでしょう。
もしそれができないのであれば、インスタンスがホストされているコンピュートノードのIPアドレスへpingを試行してください。もしそのIPにpingできるのであれば、そのコンピュートノードと、ゲートウェイ間のどこかに問題があります。
もしコンピュートノードのIPアドレスにpingできないのであれば、問題はインスタンスとコンピュートノード間にあります。これはコンピュートノードの物理NICとインスタンス vnet NIC間のブリッジ接続を含みます。
最後のテストでは、2つ目のインスタンスを起動し、2つのインスタンス間でお互いにpingを実行します。実行できるのであれば、この問題にはコンピュートノード上のファイアウォールが関係しているかもしれません。
ネットワーク問題の解決を徹底的に行う方法のひとつは、tcpdumpです。tcpdumpを使い、ネットワーク経路上の数点、問題のありそうなところから情報を収集することをおすすめします。もしGUIが好みであれば、Wireshark (http://www.wireshark.org/)を試してみてはいかがでしょう。
例えば、以下のコマンドを実行します。
tcpdump -i any -n -v 'icmp[icmptype] = icmp-echoreply or icmp[icmptype] = icmp-echo'
このコマンドは以下の場所で実行します。
クラウド外部のサーバー上
コンピュートノード上
コンピュートノード内のインスタンス上
例では、この環境には以下のIPアドレスが存在します
Instance 10.0.2.24 203.0.113.30 Compute Node 10.0.0.42 203.0.113.34 External Server 1.2.3.4
次に、新しいシェルを開いてtcpdumpの動いている外部ホストへpingを行います。もし外部サーバーとのネットワーク経路に問題がなければ、以下のように表示されます。
外部サーバー上
12:51:42.020227 IP (tos 0x0, ttl 61, id 0, offset 0, flags [DF], proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.020255 IP (tos 0x0, ttl 64, id 8137, offset 0, flags [none], proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, length 64コンピュートノード上
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019519 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.2.24 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019545 IP (tos 0x0, ttl 63, id 0, offset 0, flags [DF], proto ICMP (1), length 84)
203.0.113.30 > 1.2.3.4: ICMP echo request, id 24895, seq 1, length 64
12:51:42.019780 IP (tos 0x0, ttl 62, id 8137, offset 0, flags [none], proto ICMP (1), length 84)
1.2.3.4 > 203.0.113.30: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019801 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none], proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
12:51:42.019807 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none], proto ICMP (1), length 84)
1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64インスタンス上
12:51:42.020974 IP (tos 0x0, ttl 61, id 8137, offset 0, flags [none], proto ICMP (1), length 84) 1.2.3.4 > 10.0.2.24: ICMP echo reply, id 24895, seq 1, length 64
外部サーバーはpingリクエストを受信し、pingリプライを送信しています。コンピュートノード上では、pingとpingリプライがそれぞれ成功していることがわかります。また、見ての通り、コンピュートノード上ではパケットが重複していることもわかるでしょう。なぜならtcpdumpはブリッジと外向けインターフェイスの両方でパケットをキャプチャするからです。
Novaはiptablesを自動的に管理します。コンピュートノード上のインスタンス間でのパケット送受信、フローティングIPトラフィック、security groupのルール管理もそれに含まれます。
iptablesの現在の構成を見るには、以下のコマンドを実行します。
# iptables-save
![[注記]](../common/images/admon/note.png) | 注記 |
|---|---|
もしiptablesの構成を変更した場合、次のnova-network再起動時に前の状態に戻ります。iptablesの管理にはOpenStackを使ってください。 |
novaデータベースのテーブルには、いくつかのネットワーク情報が含まれています。
fixed_ips: Novaに登録されたサブネットで利用可能なIPアドレス。このテーブルはfixed_ips.instance_uuid列で instances テーブルと関連付けられます。
floating_ips: Novaに登録されたフローティングIPアドレス。このテーブルはfloating_ips.fixed_ip_id列でfixed_ipsテーブルと関連付けられます。
instances: ネットワーク特有のテーブルではありませんが、fixed_ipとfloating_ipを使っているインスタンスの情報を管理します。
これらのテーブルから、フローティングIPが技術的には直接インスタンスにひも付けられておらず、固定IP経由であることがわかります。
しばしば、フローティングIPを正しく開放しないままインスタンスが終了されることがあります。するとデータベースは不整合状態となるため、通常のツールではうまく開放できません。解決するには、手動でデータベースを更新する必要があります。
まず、インスタンスのUUIDを確認します。
mysql> select uuid from instances where hostname = 'hostname';
次に、そのUUIDから固定IPのエントリーを探します。
mysql> select * from fixed_ips where instance_uuid = '<uuid>';
関連するフローティングIPのエントリーが見つかります。
mysql> select * from floating_ips where fixed_ip_id = '<fixed_ip_id>';
最後に、フローティングIPを開放します。
mysql> update floating_ips set fixed_ip_id = NULL, host = NULL where fixed_ip_id = '<fixed_ip_id>';
また、ユーザプールからIPを開放することもできます。
mysql> update floating_ips set project_id = NULL where fixed_ip_id = '<fixed_ip_id>';
よくあるネットワークの問題に、インスタンスが起動しているにも関わらず、dnsmasqからのIPアドレス取得に失敗し、到達できないという現象があります。dnsmasqはnova-nwtworkサービスから起動されるDHCPサーバです。
もっともシンプルにこの問題を特定する方法は、インスタンス上のコンソール出力を確認することです。もしDHCPが正しく動いていなければ、下記のようにコンソールログを参照してください。
$ nova console-log <instance name or uuid>
もしインスタンスがDHCPからのIP取得に失敗していれば、いくつかのメッセージがコンソールで確認できるはずです。例えば、Cirrosイメージでは、このような出力になります。
udhcpc (v1.17.2) started Sending discover... Sending discover... Sending discover... No lease, forking to background starting DHCP forEthernet interface eth0 [ [1;32mOK[0;39m ] cloud-setup: checking http://169.254.169.254/2009-04-04/meta-data/instance-id wget: can't connect to remote host (169.254.169.254): Network is unreachable
インスタンスが正しく起動した後、この手順でどこが問題かを切り分けることができます。
DHCPの問題はdnsmasqの不具合が原因となりがちです。まず、ログを確認し、その後該当するプロジェクト(テナント)のdnsmasqプロセスを再起動してください。VLANモードにおいては、dnsmasqプロセスはテナントごとに存在します。すでに該当のdnsmasqプロセスを再起動しているのであれば、もっともシンプルな解決法は、マシン上の全てのdnsmasqプロセスをkillし、nova-networkを再起動することです。最終手段として、rootで以下を実行してください。
# killall dnsmasq # restart nova-network
nova-networkの再起動から数分後、新たなdnsmasqプロセスが動いていることが確認できるでしょう。
# ps aux | grep dnsmasq
nobody 3735 0.0 0.0 27540 1044 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1
--except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
root 3736 0.0 0.0 27512 444 ? S 15:40 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file=
--domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1
--except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256
--dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-roもしまだインスタンスがIPアドレスを取得できない場合、次はdnsmasqがインスタンスからのDHCPリクエストを見えているか確認します。dnsmasqプロセスが動いているマシンで、/var/log/syslogを参照し、dnsmasqの出力を確認します。なお、マルチホストモードで動作している場合は、dnsmasqプロセスはコンピュートノードで動作します。もしdnsmasqがリクエストを正しく受け取り、処理していれば、以下のような出力になります。
Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPDISCOVER(br100) fa:16:3e:56:0b:6f Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPOFFER(br100) 192.168.100.3 fa:16:3e:56:0b:6f Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPREQUEST(br100) 192.168.100.3 fa:16:3e:56:0b:6f Feb 27 22:01:36 mynode dnsmasq-dhcp[2438]: DHCPACK(br100) 192.168.100.3 fa:16:3e:56:0b:6f test
もしDHCPDISCOVERが見つからなければ、dnsmasqが動いているマシンがインスタンスからパケットを受け取れない何らかの問題があります。もし上記の出力が全て確認でき、かついまだにIPアドレスを取得できないのであれば、パケットはインスタンスからdnsmasq稼働マシンに到達していますが、その復路に問題があります。
もし他にこのようなメッセージを確認できたのであれば、
Feb 27 22:01:36 mynode dnsmasq-dhcp[25435]: DHCPDISCOVER(br100) fa:16:3e:78:44:84 no address available
これはdnsmasqの、もしくはdnsmasqとnova-network両方の問題です。(例えば上記では、OpenStack Compute データベース上に利用可能な固定IPがなく、dnsmasqがIPアドレスを払い出せない問題が発生しています)
もしdnsmasqのログメッセージで疑わしいものがあれば、コマンドラインにてdnsmasqが正しく動いているか確認してください。
$ ps aux | grep dnsmasq
出力は以下のようになります。
108 1695 0.0 0.0 25972 1000 ? S Feb26 0:00 /usr/sbin/dnsmasq -u libvirt-dnsmasq --strict-order --bind-interfaces --pid-file=/var/run/libvirt/network/default.pid --conf-file= --except-interface lo --listen-address 192.168.122.1 --dhcp-range 192.168.122.2,192.168.122.254 --dhcp-leasefile=/var/lib/libvirt/dnsmasq/default.leases --dhcp-lease-max=253 --dhcp-no-override nobody 2438 0.0 0.0 27540 1096 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file= --domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1 --except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256 --dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro root 2439 0.0 0.0 27512 472 ? S Feb26 0:00 /usr/sbin/dnsmasq --strict-order --bind-interfaces --conf-file= --domain=novalocal --pid-file=/var/lib/nova/networks/nova-br100.pid --listen-address=192.168.100.1 --except-interface=lo --dhcp-range=set:'novanetwork',192.168.100.2,static,120s --dhcp-lease-max=256 --dhcp-hostsfile=/var/lib/nova/networks/nova-br100.conf --dhcp-script=/usr/bin/nova-dhcpbridge --leasefile-ro
もし問題がdnsmasqと関係しないようであれば、tcpdumpを使ってパケットロスがないか確認してください。
DHCPトラフィックはUDPを使います。そして、クライアントは68番ポートからサーバーの67番ポートへパケットを送信します。新しいインスタンスを起動し、機械的にNICをリッスンしてください。トラフィックに現れない通信を特定できるまで行います。tcpdumpでbr100上のポート67、68をリッスンするには、こうします。
# tcpdump -i br100 -n port 67 or port 68
また、「ip a」や「brctl show」などのコマンドを使って、インターフェイスが実際にUPしているか、あなたが考えたとおりに設定されているか、正当性を検査をすべきです。
あなたがインスタンスにsshできるけれども、プロンプトが表示されるまで長い時間(約1分)を要する場合、DNSに問題があるかもしれません。sshサーバーが接続元IPアドレスのDNS逆引きをおこなうこと、それがこの問題の原因です。もしあなたのインスタンスでDNSが正しく引けない場合、sshのログインプロセスが完了するには、DNSの逆引きがタイムアウトするまで待たなければいけません。
DNS問題のデバッグをするとき、そのインスタンスのdnsmasqが動いているホストが、名前解決できるかを確認することから始めます。もしホストができないのであれば、インスタンスも同様でしょう。
DNSが正しくホスト名をインスタンス内から解決できているか確認する簡単な方法は、hostコマンドです。もしDNSが正しく動いていれば、以下メッセージが確認できます。
$ host openstack.org openstack.org has address 174.143.194.225 openstack.org mail is handled by 10 mx1.emailsrvr.com. openstack.org mail is handled by 20 mx2.emailsrvr.com.
もしあなたがCirrosイメージを使っているのであれば、「host」プログラムはインストールされていません。その場合はpingを使い、ホスト名が解決できているか判断できます。もしDNSが動いていれば、ping結果の先頭行はこうなるはずです。
$ ping openstack.org PING openstack.org (174.143.194.225): 56 data bytes
もしインスタンスがホスト名の解決に失敗するのであれば、DNSに問題があります。例えば、
$ ping openstack.org ping: bad address 'openstack.org'
OpenStackクラウドにおいて、dnsmasqプロセスはDHCPサーバに加えてDNSサーバーの役割を担っています。dnsmasqの不具合は、インスタンスにおけるDNS関連問題の原因となりえます。前節で述べたように、dnsmasqの不具合を解決するもっともシンプルな方法は、マシン上のすべてのdnsmasqプロセスをkillし、nova-networkを再起動することです。しかしながら、このコマンドは該当ノード上で動いているすべてのインスタンス、特に問題がないテナントにも影響します。最終手段として、rootで以下を実行します。
# killall dnsmasq # restart nova-network
dnsmasq再起動後に、DNSが動いているか確認します。
dnsmasqの再起動でも問題が解決しないときは、tcpdumpで問題がある場所のパケットトレースを行う必要があるでしょう。DNSサーバーはUDPポート53番でリッスンします。あなたのコンピュートノードのブリッジ(br100など)上でDNSリクエストをチェックしてください。コンピュートノード上にて、tcpdumpでリッスンを開始すると、
# tcpdump -i br100 -n -v udp port 53 tcpdump: listening on br100, link-type EN10MB (Ethernet), capture size 65535 bytes
インスタンスへのssh、ping openstack.orgの試行にて、以下のようなメッセージが確認できるでしょう。
16:36:18.807518 IP (tos 0x0, ttl 64, id 56057, offset 0, flags [DF], proto UDP (17), length 59) 192.168.100.4.54244 > 192.168.100.1.53: 2+ A? openstack.org. (31) 16:36:18.808285 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto UDP (17), length 75) 192.168.100.1.53 > 192.168.100.4.54244: 2 1/0/0 openstack.org. A 174.143.194.225 (47)